Die im letzten Artikel vorgestellte Lösung zur Umgehung des Xtend-Problems, welches das Komponieren von Konstruktor-Code mit generiertem Code, erzeugt durch den Active-Annotation-Prozessor, verhindert, ist am Ende eben nur ein Workaround – ein hässlicher noch dazu, bei dem Initialisierungscode im Konstruktor als Java-Code (mit Semikola) niedergeschrieben werden muss.
Dies veranlasste mich, noch mal grundsätzlicher über die Formalisierung einer FlowDesign-Spezifikation in Xtend nachzudenken. Ließe sich nicht auch das Anstoßen eines Flusses durch einen initialen Wert oder das Weiterleiten der Berechnungsergebnissen einer Funktionseinheit an einen Ausgabeport expliziter als durch eine Methodenimplementierung ausdrücken, um auch den Wiedererkennungeffekt beim Lesen zu erhöhen, ähnlich dem Wiedererkennungseffekt einer While-Schleife in Java am Schlüsselwort while? Und, kann man das eingangs erwähnte Problem nicht noch anders umgehen?
Nun, Xtend hat mich hier nicht enttäuscht. Am Ende ist eine richtige kleine Xtend-interne Flow-DSL entstanden, wie nachfolgend zu sehen sein wird.
XtendFlow-Operator '<='
Die Spezifikation von Verbindungen zwischen Funktionseinheiten wird ja schon mittels des speziellen Operators '->' angegeben. Es bräuchte einen ähnlichen Operator zum Weiterleiten eines Wertes an einen Eingabeport, wie z.B. nachfolgend für den Eingabeport input der Funktionseinheit fu:
"a value" => fu.input
Dies in Xtend zu implementieren wäre durchaus möglich, da Xtend es erlaubt, wie schon den Verbindungsoperator '->', auch den Operator '=>' zu überschreiben. Allerdings müsste man den Operator als Extension-Methode für die Java-Root-Klasse Object implementieren, was der Lösung die Vorteile der compilergeprüften Typsicherheit genommen hätte.
Außerdem sind viele Entwickler es eher gewöhnt, Wertzuweisungen von rechts nach links zu lesen. Deswegen habe ich mich am Ende für die umgekehrte Notation entschieden.
fu.input <= "a value"
Dies hat auch noch einen anderen Vorteil – man kann anstelle von Werten auch Closures notieren, die den weiterzuleitenden Wert berechnen.
fu.input <= [
if (len > 0)
"a value"
else
"another value"
]
Dadurch wird der Eindruck einer Kontrollstruktur erzeugt.
Um dies zu realisieren, war die Einführung der neuen Klasse InputPort notwendig, für die diese beiden Operatoren implementiert wurden. Nebenbei wird auch noch eine Asymmetrie beseitigt, die mich schon immer gestört hat, denn vorher gab es nur eine Klasse OutputPort aber keine dazu komplementäre Klasse zur Verarbeitung von Eingaben.
Der Active-Annotation-Prozessor fügt zusätzlich noch gleichnamige Operatoren generativ Funktionseinheiten hinzu, die nur einen Eingabeport haben. So daß bei solchen Einheiten der Namen des Eingabeport weggelassen werden kann.
Dadurch lässt sich der Datenfluss in unserem Beispiel nunmehr mit den folgenden beiden Alternativen anstossen.
reverse <= palindrom reverse.input <= palindrom
Fehlt noch das Weiterleiten eines Berechnungsergebnisses an den Ausgabeport einer Funktionseinheit. Dazu wird die bereits vorhandene Klasse OutputPort um eben diese beiden Operatoren erweitert. Damit wird es möglich, die Beispiel-Klasse Reverse nunmehr auf folgende Weise zu implementieren.
@FunctionUnit(
inputPorts = #[
@InputPort(name="input", type=String)
],
outputPorts = #[
@OutputPort(name="output", type=String)
]
)
class Reverse {
override process$input(String msg) {
output <= [
val reversedMsgBuilder = new StringBuilder
var index = msg.length
while (index > 0) {
index = index - 1
reversedMsgBuilder.append(msg.charAt(index))
}
reversedMsgBuilder.toString
]
}
}
In Zeile 11 bis 19 ist die neue Zuweisung implementiert, wobei der Namen des Ausgabeports in Zeile 11 genau dem deklarierten Namen des Ports in Zeile 6 entspricht. Die Generierung eines Ausgabeports als Getter des Typs OutputPort mit dem Namen des Ports wird durch den Active-Annotation-Prozessor gewährleistet und impliziert In Eclipse entsprechende Vorschläge durch das Auto-Completion- und Quick-Fix-System (bei Umbenennung).
Hier ist auch gleich noch eine Änderung zu den vorhergehenden Versionen zu sehen: In Zeile 10 wird der Name des Eingabeports, hier input, mit einem Dollarzeichen vom Präfix process getrennt. Gemeinsam ergeben sie den Namen der Methode, die die Verarbeitung des Eingabestroms implementiert, der über den benannten Eingabeport in die Funktionseinheit einfließt. Damit ist eine direkte Namenskorrelation zwischen der Deklaration des Eingabeports in der Annotation und der zugehörigen Datenverarbeitungsmethode gegeben und erleichtert das Wiedererkennung einer zum Eingabeport gehörenden Implementierung.
XtendFlow-Operator '->'
Den Verbindungsoperator gab es ja in der vorhergehenden Version bereits. Jedoch war er nicht auf die eigenen Eingabe- und Ausgabeports einer Funktioneinheit anwendbar, was die Spezifikation von Funktionseinheiten, die nur intergieren (apropos @Wiring) relativ umständlich machte.
Führt man sich alle möglichen Notationen für Ports und Closures auf beiden Seiten eines Verbindungsoperators vor Augen, dann ergeben sich folgende Kombinationen:
fu -> fu' fu -> fu'.input fu.output -> fu' fu.output -> fu'.input fu.output -> [closure] fu -> [closure]
In Zeile 1 werden zwei Funktionseinheiten verbunden, die jeweils nur einen Ausgabeport und einen Eingabeport haben. In der zweiten Zeile hat fu nur einen Ausgabeport, aber fu' möglicherweise mehr als einen Eingabeport. In Zeile 3 hat fu' nur einen Eingabeport, aber fu möglicherweise mehr als einen Ausgabeport. Zeile 4 zeigt eine Verbindung zwischen 2 Ports mit voll qualifizierten Namen. Und die letzten beiden Zeilen zeigen die Verarbeitung der Ausgaben zweier Funktionseinheiten durch eine Closure.
Der Active-Annotation-Prozessor gewährleistet, dass alle Funktionseinheiten gemäß der Annotationsspezifikation mit den entsprechenden benannten InputPorts und OuputPorts angereichert werden, so dass alle oben genannten Operationen anwendbar sind.
Insbesondere die Spezifikation des Datenflusses in integrierenden Funktionseinheiten wird dadurch einfacher. So können zum Beispiel die Funktionseinheiten der ursprüngliche Beispielfunktionseinheit Normalize auf folgende Weise mit einander verbunden werden.
new() {
input -> toLower
input -> toUpper
toLower.output -> lower
toUpper.output -> upper
}
Die ersten beiden Zeilen des Konstruktors verbinden die Eingabeports der integrierenden Funktionseinheit Normalize mit jeweils dem Eingabeport der beiden integrierten Funktionseinheiten toLower und toUpper und delegieren die Verarbeitung des Eingabestroms damit an diese, während die Ausgabeports dieser beiden Funktionseinheiten jeweils mit einem Ausgabeport der integrierenden Funktionseinheit verbunden werden. Damit ist dies die direkte Umsetzung des ursprünglichen FlowDesign-Diagramms in der Notation, die ursprünglich auch für EBCs und in der Flow-Runtime NPantarhei verwendet wurde.
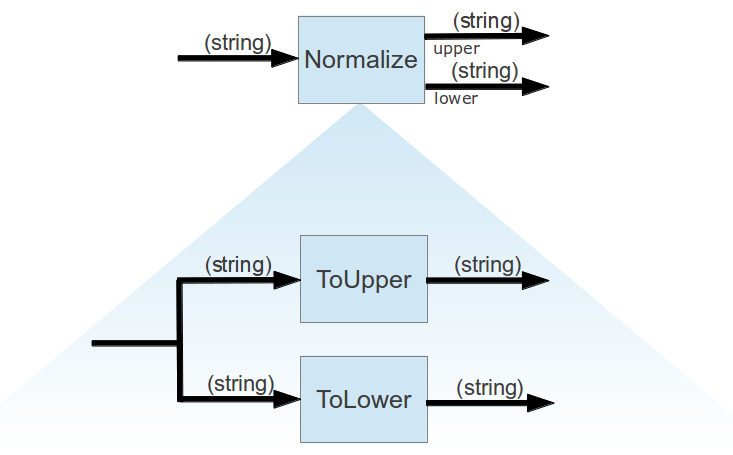
Eine integrierende Funktionseinheit besteht damit eigentlich, wie weiter unten auch zu sehen sein wird, nur noch aus den Feldvariablen für die integrierten Funktionseinheiten und dem Konstruktor, der deren Verbindung definiert.
Annotation @FunctionBoard
Um Funktionseinheiten, die andere Funktionseinheiten integrieren, von solchen explizit zu unterscheiden, die echte Funktionalität implementieren, habe ich die Annotation @FunctionBoard eingeführt.
Ich halte die strikte Trennung integrierender Komponenten von funktionalen Komponenten für eines der grundlegenden Prinzipien von Flow-Design, von Ralf Westphal als Integration Operation Segregation Principle (IOSP) auf den Punkt gebracht. Dieses Prinzip erlaubt es Software-Systeme sauber in Hierarchieebenen zu gliedern, die jedem Leser eines Flow-Designs beginnend mit dem System-Umweltdiagramm mit absteigender Abstraktion das Verstehen eines Systems erlauben. Dabei stellt jedes FunctionBoard eine eigene Abstraktionebene dar, die den Datenfluss zwischen den in ihm integrierten Funktionseinheiten repräsentiert und verständlich macht.
Zusammen mit den neu eingeführten Verbindungsoperationen lässt sich die ursprüngliche Implementierung der Funktionseinheit Normalize nunmehr sehr kompakt und deklarativ spezifizieren als
@FunctionBoard(
inputPorts = #[
@InputPort(name="input", type=String)
],
outputPorts = #[
@OutputPort(name="lower", type=String),
@OutputPort(name="upper", type=String)
]
)
class Normalize {
val toLower = new ToLower
val toUpper = new ToUpper
new() {
input -> toLower
input -> toUpper
toLower.output -> lower
toUpper.output -> upper
}
}
DSL-Implementierungsdetails
Die meisten Operationen sind direkt in den beiden komplementäre Klassen InputPort und OutputPort implementiert. Die Operatoren für Funktionseinheiten mit nur einem Eingabe- bzw. Ausgabeport werden bei Bedarf generativ durch den Active-Annotation-Prozessor in der generierten Java-Klasse erzeugt indem das Interface FunctionUnitWithOnlyOneInputPort respektive FunctionUnitWithOnlyOneOutputPort implementiert wird. Die folgende Tabelle listet die Operatoren und die Klassen, die sie definieren sowie deren Signatur auf.
| Notation | Signatur |
|---|---|
| FunctionUnitWithOnlyOneOutputPort | |
| fu -> fu' | -> (FunctionUnitWithOnlyOneInputPort <MessageType>) |
| fu -> fu'.input | -> (InputPort<MessageType>) |
| fu -> .output | -> (OutputPort<MessageType>) |
| fu -> [closure] | -> (()=><MessageType>) |
| FunctionUnitWithOnlyOneInputPort | |
| fu <= input value | <= (<MessageType>) |
| fu <= [closure] | <= (()=><MessageType>) |
| InputPort | |
| fu.input <= input value | <= (<MessageType>) |
| fu.input <= [closure] | <= (()=><MessageType>) |
| .input -> fu.input | -> (InputPort<MessageType>) |
| .input -> fu | -> (FuntionUnitWithOnlyOneInputPort<MessageType>) |
| OutputPort | |
| fu.output -> fu' | -> (FunctionUnitWithOnlyOneInputType<MessageType>) |
| fu.output -> fu'.input | -> (InputPort<MessageType>) |
| fu.output -> .output | -> (OutputPort<MessageType>) |
| fu.output -> [closure] | -> (()=><MessageType>) |
| .output <= output value | <= (<MessageType>) |
| .output <= [closure] | <= (()=><MessageType>) |
Die Notationsbeispiele mit führendem Punkt in der Tabelle, wie z.B. ".output", beziehen sich auf Referenzierungen von Ports die durch die Instanz der Funktionseinheit selber definiert werden, im Unterschied zur Referenzierung instanzfremder Ports, wie z.B. "fu.output".
Das Projekt hat noch eine andere Code-Design-Änderung erfahren: Alle Funktionseinheiten leiten nicht mehr von Klasse FunctionUnitBase ab. Stattdessen implementieren alle Klassen das neue Interface IFunctionUnit. Alle in FunctionUnitBase ursprünglich implementierten Methoden, vor allem zur Fehlerbehandlung, werden jetzt generativ als Implementierung des neuen Interfaces durch den Active-Annotation-Prozessor erzeugt. Somit steht einer benutzerspezifischen Ableitungshierarchie nichts mehr im Wege, auch wenn sie nicht empfehlenswert ist! Eine Komposition über FunctionBoards ist immer vorzuziehen.
Bauen und Verteilen
Das Projekt wurde auf Gradle als Build-System umgestellt. Dabei kommt das Xtend Gradle Plugin des Xtend-Teams zur Anwendung. Das Release wird mit Hilfe des Gradle Plugins sobula.bintray-release von Stefan Öhme auf bintray und Maven bereitgestellt.
Der Continues-Integration-Service travis-ci.org baut das Projekt bei jedem GitHub-Commit und jedem über GitHub annoncierten Release.
Randnotiz
Im GitHub-Readme des Projektes steht eine Zusammenfassung auf Englisch zur Verfügung.
Dieser Artikel basiert auf der Version 0.3.0 der XtendFlow-Bibliothek.