
Why is software engineering so different from all other engineering dealing with real parts? Why is the design of a software system almost not recognizable anymore in the code?
I’m quite sure, software engineering can get closer to how other engineering disciplines are doing it. It is possible to make design directly recognizable in code. This blog article series is about a possible approach.
Look at this block diagram about an Apple I Video Terminal:
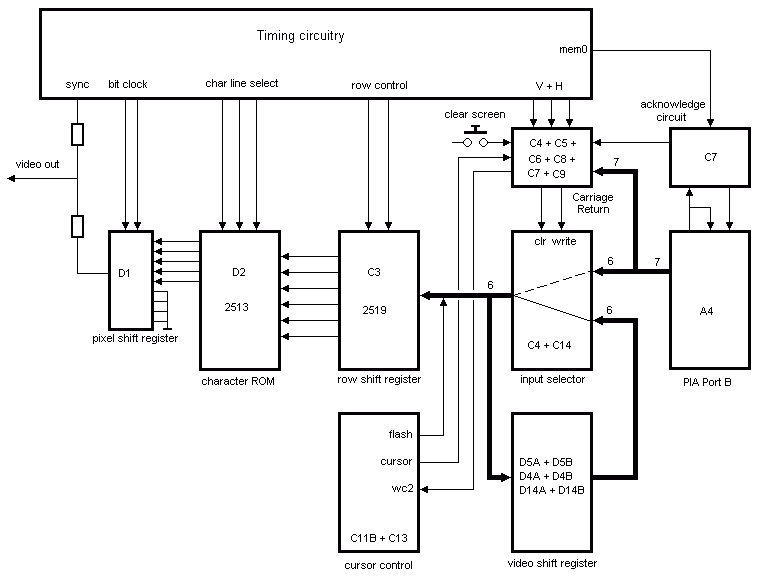
It describes in an abstract way the components the video terminal is build from and how they interact and depend on. E.g., data is flowing from row shift register component C3 to the character ROM component D2. All is clear. D2 depends in this context on C3.
If implementing this in software, how would it look like?
I guess, we could implement the D2 component as class where a character can be selected from outside to be displayed:
class D2 {
void select(char c)
}
Fine. C3 could also be designed as class that calls D2 as C3 depends on D2:
class C3 {
void shiftTo(char c) {
D2.select(c)
}
}
Do you see the difference between the software implementation and the real part realization?
In both cases C3 depends on D2. But only in software C3 has to know D2 to satisfy the required dependency. In the real world parts, each part exists independent from all other parts. Only the context, here the video board, creates the dependencies. However, in the software solution the class C3 could never be used without D2; it could not exist without it. In the material world on other board designs, the C3 circuit could be used differently and connected to other circuits without D2 being involved at all. C3 and D2 exist independent of each other.
You may reply, interface with dependency injection would do the work and solve the problem. We could write
interface ID2 {
void select(char c)
}
class C3 {
@Inject ID2 d2;
void shiftTo(char c) {
d2.select(c)
}
}
I do not agree! The problem with methods and function is, there is semantic bound to them, typically. Again, let’s compare it to real electronic parts. There are also interfaces involved. Typically, IC C3 would have a data sheet specifying the input constraints for its input pins. This is like an interface description. And, it would be described without referencing the D2, of course, as it was designed originally without knowing D2, probably. But look at the code above. Here the input is coming from D2 through interface ID2. And C3 is specified based on that input; C3’s “input pin” shiftTo() is specified using ID2. C3 is definitely not independent of at least ID2.
The real problem here is, the method select has a meaning, let it be part of D2 or of ID2; C3 cannot exist independent of D2 or ID2 for that meaning. But it should. And, it can! We see it in the real parts world every day. OOD as we use it today is simply not sufficient for modeling typical real world scenarios, as we see.
Ralf Westphal, where I had the idea for this article from, is calling this independence of parts, the Principle of Mutual Oblivion (PoMO).
So, why not apply this principle to software design too? And, how to do that?
It’s worth to look back how Alan Key had introduced OOD:
I thought of objects being like biological cells and/or individual computers on a network, only able to communicate with messages (so messaging came at the very beginning — it took a while to see how to do messaging in a programming language efficiently enough to be useful)
Alan Key did not define what messaging means. I found Ralf Westphal’s definition concise and snappy:
Messaging is one-way communication by transporting data (message) from a sender to a receiver.
If you look at the call to D2.select(c) in the example above it violates this in a very subtle way. It seems to pass the data hold by argument c only in direction to D2. But in fact, we must not forget the control flow. It returns back to the caller! If it would be a function (instead of a void method), it would be obvious. Functions are not one way communications; but, void methods too. The control flow is making the subtle difference. It communicates back: message is send and processed. So, in that way methods in todays object oriented languages violates that definition of messaging and prevent from applying Alan Key’s original intend for OOD.
How to do it different?
Message Passing
There are very successful programming models out there based on messaging. Take the Unix command shell and its pipe operator as an example. The pipe operator connects functional units by process line based messages.
This approach will not fit for the domains, general purpose languages are intended for. But it shows quite well the main idea, how the Principle of Mutual Oblivion (PoMO) may be applied. And, it is quite well known.
Here is an slightly adapted example of find-requires from the rpm tool set (the original may be found here)
#!/bin/sh ulimit -c 0 . ./determineLibraryDependencies.sh echo $* | determineLibraryDependencies | sort -u -r | xargs -r -n 1 basename
The script determines for a list of given files their shared library requirements by applying the shell script function determineLibraryDependencies (locally defined in the shell script determineLibraryDependencies.sh) on each, producing a list of .so-names. Finally, the list of .so-names is sanitized by sorting, removing duplicates, and removing any paths.
For each step described here, it uses a functionality almost pre-implemented and provided by the operating system or by another script. And, look only on the last line; it shows the main reason of this script itself: It integrates several commands to build a new functionality. It does not define functionality itself. There is no logical expression or control statement in this script beside connecting commands together using the pipes. This principle is quite often found in shell script based systems. And, it is easy to understand and quite easy to extend.
The function determineLibraryDependencies itself is defined as
determineLibraryDependencies() {
read input
for f in $input; do
ldd $f | awk '/=>/ { print $1 }'
done
}
Even if this looks like a method, it is not a method in the sense of object oriented languages! It takes its input from the standard input stream not knowing, who will provide it. And more important: it is forwarding its result to the standard output stream, not knowing who will consume it. It is really independent of any functionality in its context in the sense of PoMO. It contains business logic as it is calling ldd for its main purpose . In that sense it has operational semantics — it’s an operation.
If running this find-requires script against e.g. the binary aconnect then the following output is generated:
denis@scala:$ ./find-requires /usr/bin/aconnect linux-gate.so.1 librt.so.1 libpthread.so.0 libm.so.6 libdl.so.2 libc.so.6 libasound.so.2
Let’s extend the functionality by replacing one of the components to get the dependencies sorted by full paths instead of the libraries base names. For that, the input of the sorting command must be the full paths of the libraries. A new operation which implements this functionality is added to determineLibraryDependencies.sh:
determineFullPathLibraryDependencies() {
read input
for f in $input; do
ldd $f | awk '/=>/ { if ( $3 == "" || match($3, "0x")) {print $1} else {print $3} }'
done
}
Now only the integration in find-requires is adapted using the new command:
echo $* | determineFullPathLibraryDependencies | sort -u -r | xargs -r -n 1 basename
Flow Design
I did not need to change any functionality up or down the flow. The operation “echo $*” don’t know determineFullPathLibraryDependeny, just as the operation “sort -u -r” down the flow. There is no logic changed in find-requires. It’s only purpose is to integrate. And so, the only reason for a change in find-requires is a change to what is going to be integrated.
This kind of design, where the data flow is modeled flowing trough and being modified by operations, concatenated by integration units, we call Flow Design.
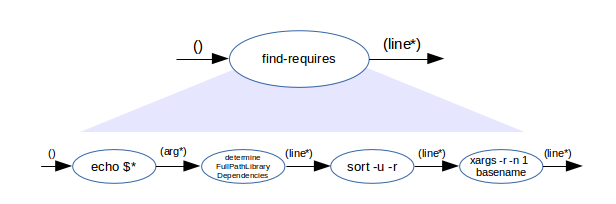
Flow Designs are easy to draw. There are only a small number of drawing elements. Here is the flow design diagram for the find-requires command from above.
 The bubbles are functional units. They are connected through arrows denoting the direction of the flow. Above the arrows, the data type is annotated in braces. Empty braces indicates signals without specific data (e.g., like program starts). If more than one input to or output from a functional unit wants to be designed, they may be annotated by pin names like stdin and stdout in this example. That’s all and quite similar to the box-bullet-line notation approach. Only the dependency notation is lacking in this example due to its simplicity. For details of this notation, see the flow design cheat sheets.
The bubbles are functional units. They are connected through arrows denoting the direction of the flow. Above the arrows, the data type is annotated in braces. Empty braces indicates signals without specific data (e.g., like program starts). If more than one input to or output from a functional unit wants to be designed, they may be annotated by pin names like stdin and stdout in this example. That’s all and quite similar to the box-bullet-line notation approach. Only the dependency notation is lacking in this example due to its simplicity. For details of this notation, see the flow design cheat sheets.
The top of the design is the functional unit find-requires. It is drawn similar with the input type of the left most unit and output type of the rightmost unit it aggregates. This top-most functional unit and the flow from above denotes different levels of abstraction. It is like zooming in when looking into the find-requires unit to figure out, what it integrates.
 Back to our example: Running the whole command again show a slightly different output – different sorted:
Back to our example: Running the whole command again show a slightly different output – different sorted:
denis@scala:$ ./find-requires /usr/bin/aconnect libasound.so.2 linux-gate.so.1 librt.so.1 libpthread.so.0 libm.so.6 libdl.so.2 libc.so.6
The reason for that is quite easy to discover. Just interrupt the flow before the sort command for both different shell functions. You will see the different input flowing into the sort command. So, flows are also very easy to debug and by the way, independent operations very easy to test. No mocking frameworks are needed anymore.
This was easy to extend, isn’t it? And, all functional operations has been left untouched. We had only added the new operation determineFullPathLibraryDependencies and changed the script where all is integrated. Single Responsibility Principle (SRP) at its best, which postulates that an implementation component should have only one reason to change.
However, in object oriented designs we would typically have to call the new function/method in the method which is coming prior in the control flow, like the call to D2.select() in C3, even if there is no reason at all to change the component prior in the control flow…
So, what is the main reason for the easy extensibility of those Unix script? If you look closer to the functional units of shell based software systems, you’ll see, they are often build from shell scripts and commands from different authors. They themselves typically have build them not knowing in which context their functional units will be used later on. Moreover, each shell script command is programmed to be strictly independent from other ones. It does not know the context it will be used in and is protected from other ones by being encapsulated into a process by the operating system.The only interfaces are the stdin and the stdout pipes and message types flowing in and out.
For the user of the shell scripts and commands it’s the same, they do not want know how the functionality of the particular command is implemented. They just need to know their functionality and how the input lines and output lines are structured. Therefore it is quite easy to extend or adapt an existing functionality by incorporating another shell script command in a flow just by cutting a pipe where needed and letting the old output pointing to the incorporated functional units input whereas its output is connected to the functional unit’s input down the flow.
IODA Architecture
However, shell based software systems show up another principle which is worth to be reused in software designs in general: New shell functionality is created just by connecting existing commands together through the pipe operator. On a higher level of abstraction those again may combined to new shell scripts. If only the pipe operator is used, no control structures like if-then-else or for-loop, then the only responsibility of such a shell script is integration. However, this shell script itself consumes the standard input stream and provides results on the standard output stream — from outside it looks like an operation, it’s a functional unit like other operations, and therefore may be used again in other scripts defining a new flow on a higher level of abstraction.
Building new functional units based on existing functional units, let it be operations or integrations, without mixing in logic and control flow into the integrating functional units, results in a tree of functional units with clear levels of abstraction where all operations (the O in IODA) are leafs, and integrations (the I in IODA) are nodes. All functional logic is in the operations only. All integration logic is in integration units only. Data (the D in IODA) is flowing from one functional unit to the other. And here, in designing the types of data, OOD would be a very valuable design principle, I would not like to miss. Down the road, operations are using frameworks and APIs (the A in IODA) to operate on the underlying operating system or hardware or specific frameworks.
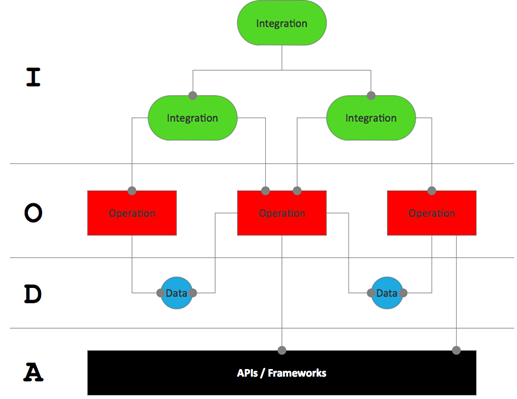
The IODA architecture is describe in detail in Ralf Westphal’s article. It is more general than Flow Design and applicable to any programming paradigm. However, Flow Design approaches automatically result in an IODA architecture.
Flow Design and IODA Architecture in Multi-purpose Programming Languages
Of course, shell commands are restricted to receive one type of input and provides exactly the same type of output – streams of character lines. In that sense they are unsuitable for being used in general purpose programming, as the data is unstructured and untyped. However, if you get into the unstructured message type, there may be built very successful software systems based on that. Successful in terms of maintainability and extensibility! A lot of shell based software systems in the Unix world demonstrates this quite well.
Even, if a programming language does not support the message driven paradigm directly, Flow Design is possible to be done quite easily on those language. The only precondition is the support of something like function objects. So, delegates and events (C#) will fit as well as lambda function (Java), closures (Scala, Groovy, Ruby).
In the next article I will show, how to realize flow designs in Java, Scala and Xtend quite concise, partly supported by small libraries introducing internal DSLs for wiring up functional units.
Stay tuned…
Pingback: Let It Flow in Java – Beyond Coding